The Short Version
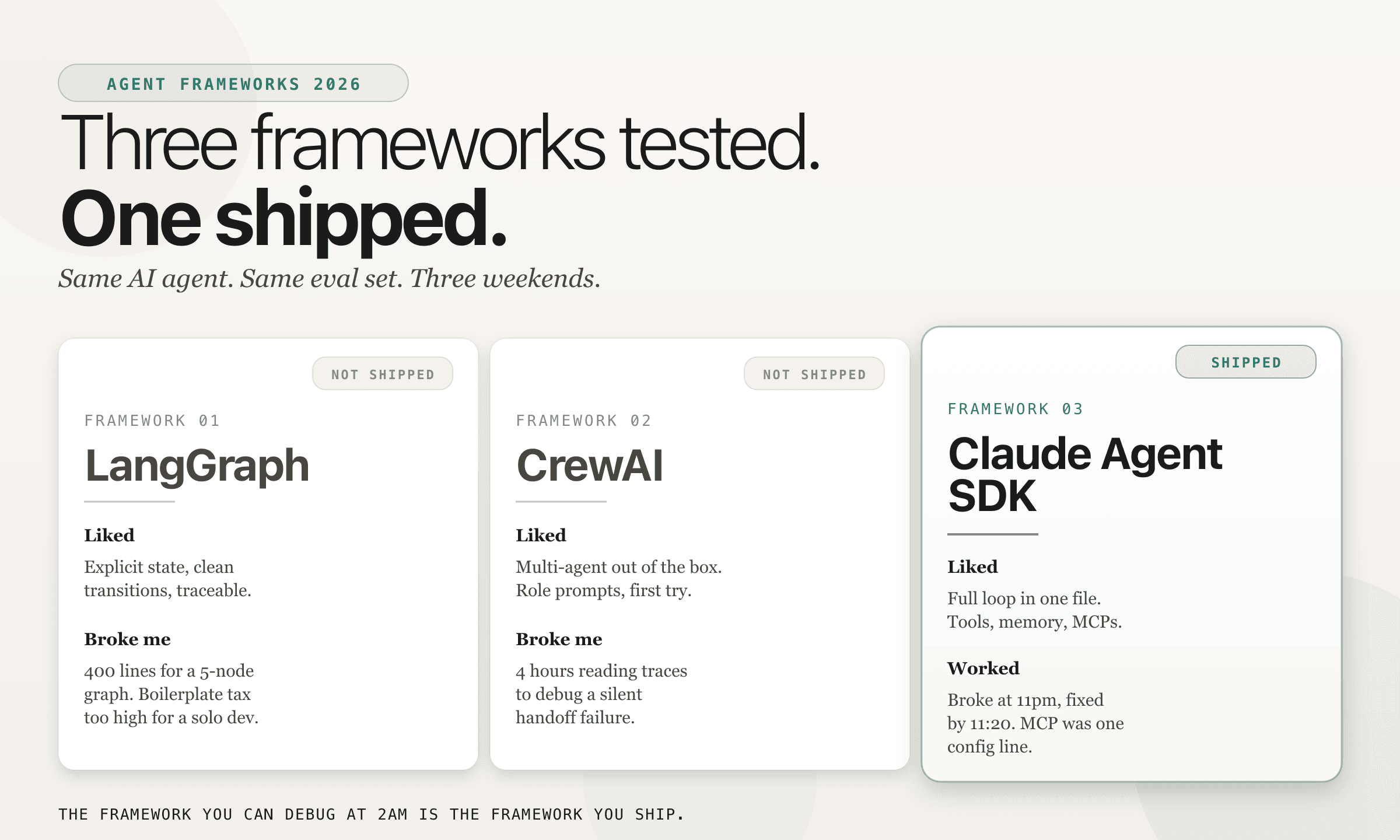
I built the same AI agent in three frameworks last month. Only one shipped.
I am building Alma solo. The matching agent has to read a mentor profile and draft a 3-line warm intro to a specific student. And it has to not read like ChatGPT. That last constraint is the hard one, and it is the reason the framework underneath matters.
The Eval Set
Before I touched any framework I wrote the eval. 80 test cases. Each case has a student profile and a mentor pool of 20 to 30. Output is a ranked mentor plus a 3-line intro note.
The metric is not BLEU score or any LLM-as-judge contraption. The metric is reply rate from the mentor after one week. Everything else is vanity.
Every framework got the same prompts, the same tools, the same Claude Sonnet 4.6 backing. The only thing that changed was the plumbing.
LangGraph
Side-by-side code · rank mentors then draft a 3-line intro
from langgraph.graph import StateGraph, END
from typing import TypedDict
class MatchState(TypedDict):
student: dict
pool: list[dict]
ranked: list[dict]
intro: str
def rank(state: MatchState) -> MatchState:
state["ranked"] = score_with_claude(state["student"], state["pool"])
return state
def draft(state: MatchState) -> MatchState:
state["intro"] = write_intro(state["student"], state["ranked"][0])
return state
g = StateGraph(MatchState)
g.add_node("rank", rank)
g.add_node("draft", draft)
g.set_entry_point("rank")
g.add_edge("rank", "draft")
g.add_edge("draft", END)
app = g.compile()
out = app.invoke({"student": s, "pool": p, "ranked": [], "intro": ""})What I liked. Explicit state. Clear transitions. Every node logs a trace you can read linearly. If you come from a systems background, LangGraph feels correct. You model your agent as a graph, not as a vibe.
What broke me. 412 lines for a 5-node graph. Schema definitions, edge conditions, state reducers. On a team, that structure pays off. Solo, it is a boilerplate tax I was paying in hours I did not have.
Verdict. Good for teams shipping production agents with multiple engineers maintaining state contracts. Too heavy for a one-person shop.
CrewAI
Side-by-side code · same task, two role-based agents
from crewai import Agent, Task, Crew
ranker = Agent(
role="Mentor Ranker",
goal="Rank mentors by fit for a given student.",
backstory="You know Alma's mentor pool inside out.",
)
writer = Agent(
role="Intro Writer",
goal="Draft a 3-line warm intro.",
backstory="You write like a friend, not a recruiter.",
)
rank_task = Task(description="Rank pool for student.", agent=ranker)
intro_task = Task(
description="Write a 3-line intro to the top pick.",
agent=writer,
context=[rank_task],
)
Crew(agents=[ranker, writer], tasks=[rank_task, intro_task]).kickoff()What I liked. Multi-agent out of the box. I set up two role-based agents and the role prompts worked on the first try. The mental model is clean.
What broke me. I spent 4 hours reading traces to debug a silent handoff failure. The Intro Writer was getting an empty context from the Mentor Ranker and confidently writing an intro to nobody. No error. No warning. The abstraction hides exactly the thing you need to see when it breaks.
Verdict. A beautiful abstraction until you need to see inside. For prototypes it is delightful. For shipping, I need to see the raw messages.
Related Resources
AI Agents for Mechanical Engineers
Agent frameworks, browser automation, local AI, and MCP connectors filtered through an engineering lens.
Technical Deep DiveUsing Claude to Debug Hydraulic Simulations
How structured prompts found a buried 10x coefficient error in 90 seconds.
Resource PostF-1 to Founder: The 36-Month Playbook
OPT, STEM OPT, and the founder path, phase by phase, for international students.
Follow me on LinkedIn for weekly builder logs from solo founder land
Follow on LinkedInMore resources coming soon
← Back to all resources